On Episode 2 of the Google Developers Machine Learning Recipes with Josh Gordon Youtube series we are looking at the Iris Flowers Data set and are going to attempt to make a Decision Tree using TensorFlow to classify 3 different species of iris flowers.
Prerequisites
I am using MacOS for my development so if you are running Linux, Windows, or are throwing rocks to make sparks you might need to change accordingly. I used conda (Anacondas Package Manager) to create a python environment for the application.
It is recommended to use either Docker containers or python virtual environments for projects like this. In order to create the python environment for TensorFlow I ran the following command in terminal:
conda create -n tensorflow_env TensorFlow
This will create a python environment with the base level packages needed including TensorFlow. From there all you have to do is activate the python environment in your terminal session:
conda activate tensorflow_env
Now we are in the activated python environment so any scripts for the TensorFlow guide that need specific imports will be able to run with no problems.
The code I used is available on my github
My thoughts on the video
This is my first real hands on experience with TensorFlow and understanding training and testing of data. It was pretty simple to load the data. All you need to do it run: iris = load_iris() since the dataset is already in the sklearn dataset. sklearn is from my understanding a neural network library that allows us to create neural networks for training, testing, and eventually predicting.
First, we needed to scrub the data which is really important before we start training. Since the dataset is pretty much ready to go all we needed to do was remove a few entries in the database to use for testing
test_idx = [0,50,100]
train_target = np.delete(iris.target, test_idx)
train_data = np.delete(iris.data, test_idx, axis = 0)
#testdata
test_target = iris.target[test_idx]
test_data = iris.data[test_idx]
clf = tree.DecisionTreeClassifier() #classifier
clf.fit(train_data,train_target)
We remove the data and train the data with a decision tree model. Then we test the data with the removed flower to act as a “prediction” that we can check for correctness.
print(clf.predict(test_data))
print(test_data[0], train_target[0])
The data does match what was in the iris database beforehand, so we had a successful prediction. All that’s left is to visualize the decision tree
import graphviz
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph.render("iris")
#Testing some predictions looking at the Visualized Tree
print(test_data[0], test_target[0])
print(test_data[1], test_target[0])
#Questions go from Right to Left when making decisions
print(iris.feature_names, iris.target_names)
The decision tree was printed to a pdf that I will place below. You will see the tree used the features of the database like petal width and length to determine where to split the tree.
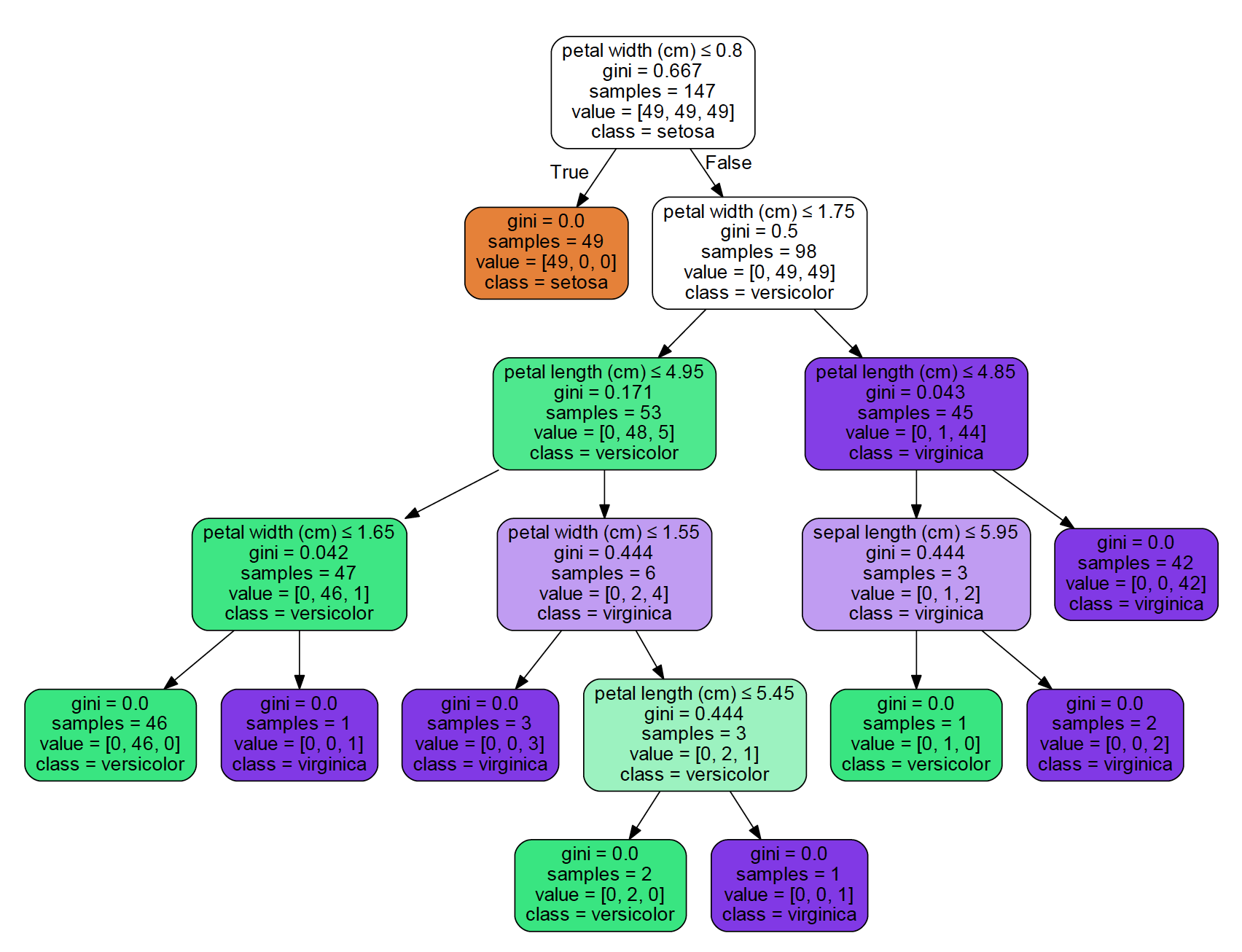
Overall this lab was a great introduction to some Machine Learning Concepts as well as TensorFlow. Every question a Tree asks must be about your Features. That means the better your features are, the better a tree you can build. I am excited to learn about the other classification methods other than decision trees in the future.
On a final note, Irises are funny looking flowers.

Sources
Developers, Google. “Visualizing a Decision Tree - Machine Learning Recipes #2.” YouTube, YouTube, 13 Apr. 2016, www.youtube.com/watch?v=tNa99PG8hR8&list=PLOU2XLYxmsIIuiBfYad6rFYQU_jL2ryal&index=3&t=5s.
